超軽量CMSを作った
npm publishしてみた
npmにmb_strwidthというpackageをpublishしました。
PHPの mb_strwidth() と同じ動きをする関数です。
https://www.npmjs.com/package/@demouth/mb_strwidth
https://github.com/demouth/mb_strwidth
console.log(mb_strwidth('𩸽定食食べたい😭')); // 15
// PHP 7.3.28
var_dump(mb_strwidth('𩸽定食食べたい😭')); // int(15)
動機
npmのpackageの公開ってどういう感じなのか知りたかったので、昔書いたgistを少し書き換えて公開してみました。 別にmb_strwidth()をJSで使いたかった訳ではないです。
参考にしたのはこちらの記事で、ほぼこの通りにやっただけです。 https://zenn.dev/manycicadas/books/b6f2d99b5208e9
以上。
Writing A Compiler In Goを完走した
去年の夏に書籍「Writing A Compiler In Go」を購入して以降、時間を見つけてコツコツ進めていたのですが、先日ようやく完走することができました。
基本的には本に書いてあることを写経しながら進めるだけでコンパイラが完成してしまうので、内容をしっかり理解していなくても完走はできてしまいます。なので、記憶の定着を目的にこの本で何をやったのかブログに残しておこうと思います。
目次
- 「Writing A Compiler In Go」とは
- 前作「Writing An Interpreter In Go」でやったこと
- 「Writing A Compiler In Go」で何をやるか
- 終わりに
「Writing A Compiler In Go」とは

「Writing A Compiler In Go」という本ですが、これの前作にあたる「Writing An Interpreter In Go」の日本語訳が「Go言語でつくるインタプリタ」としてオライリーから出ているので、ご存じある方も多いかと思います。 私は数年前に「Go言語でつくるインタプリタ」を読んでいて、続編の日本語訳が出版されるのを待っていたのですが、いつまで経っても発売されないので昨年英語版を購入しました。
「Writing A Compiler In Go」を超簡単に説明すると「写経しながら軽量な自作コンパイラを作ってみよう」という本です。 前作「Writing An Interpreter In Go」で実装したインタプリタを書き換えることで、Virtual Machine(VM)上で動作するようになります。
コンパイラを作るというと、想像もつかないくらい難しいことをやるんじゃないかと身構えてしまいますが、この本は小さなテストを先に書いてから小さな実装を書き、それを何度も積み重ねながら進んでいきます。そして気がついた頃にはいつの間にかVMと、そのVM用のバイトコードを生成するコンパイラを完成している、という感じで意外とつまずくことなく最後まで辿り着くことができてしまいます。
前作「Writing An Interpreter In Go」でやったこと
その前に前作「Writing An Interpreter In Go」でやったことを振り返っておこうと思います。 前作では「Monkey言語」というJS風のオリジナル言語を定義し、そのインタプリタを実装しました。
Monkey言語はこんな感じの言語です。
// Monkey言語の一例
let people = [{"name": "Anna", "age": 24}, {"name": "Bob", "age": 99}];
let getName = fn(person) { person["name"]; };
getName(people[0]); // => "Anna"
getName(people[1]); // => "Bob"
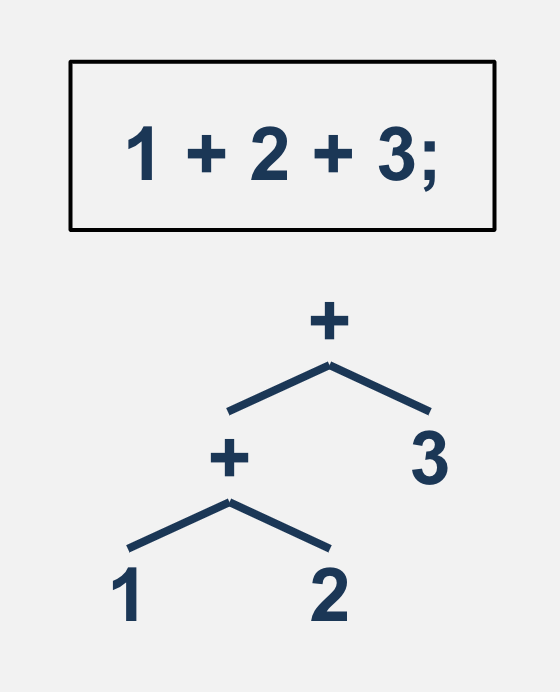
入力となるMonkey言語に対して、字句解析、抽象構文木解析、評価を順番にしていくことでMonkey言語を実行します。
下図のように最初はただの文字列として扱われていたプログラムが順に処理されていくことで実行結果を得ることができます。 図では「10 + 2;」を順に評価して、12という結果を得ています。

ここまでが前作「Writing An Interpreter In Go」でやったことのおおまかな流れです。
つぎに字句解析と抽象構文木解析についても軽く復習します。
字句解析 Laxer
字句解析では文字を1文字ずつ読み進めていき、意味のあるところで区切っていきます。 例えば「let number = 2;」だったら「l」「e」「t」…という感じで1文字ずつ読み進め、行頭から「let」という字句を見つけることで、これは「let」トークンだ、と識別します。

構文木解析 Parser
先ほど字句解析にかけたものをもとに、今度は構文木解析します。 意味のある形にまとめられ、ツリー状のデータ構造になります。
ちなみに既存のパーサージェネレータは使用せず、自前のパーサー(Pratt構文解析器)を実装します。
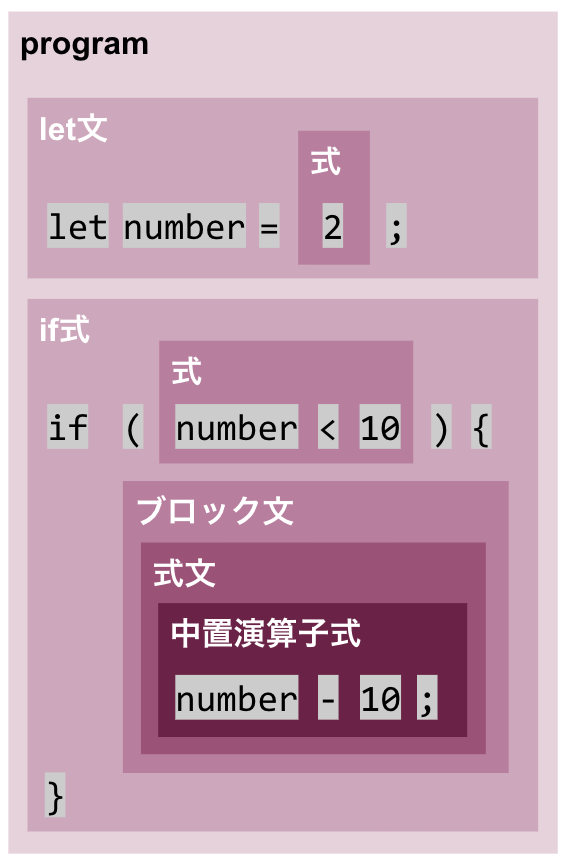
評価 Eval
Tree-Walkingインタプリタを実装します。 この実装方式では、抽象構文木を辿り、順に評価していきます。
難しそうな感じがしますが、前処理の構文木解析によってすでにツリー状なっているので、あとは実行するだけです。意外に単純。
「Writing A Compiler In Go」で何をやるか
ここまでが前作「Writing An Interpreter In Go」でやったことでした。
そして、これを踏まえて「Writing A Compiler In Go」ではインタプリタを下図のように書き換えます(赤色の部分)。
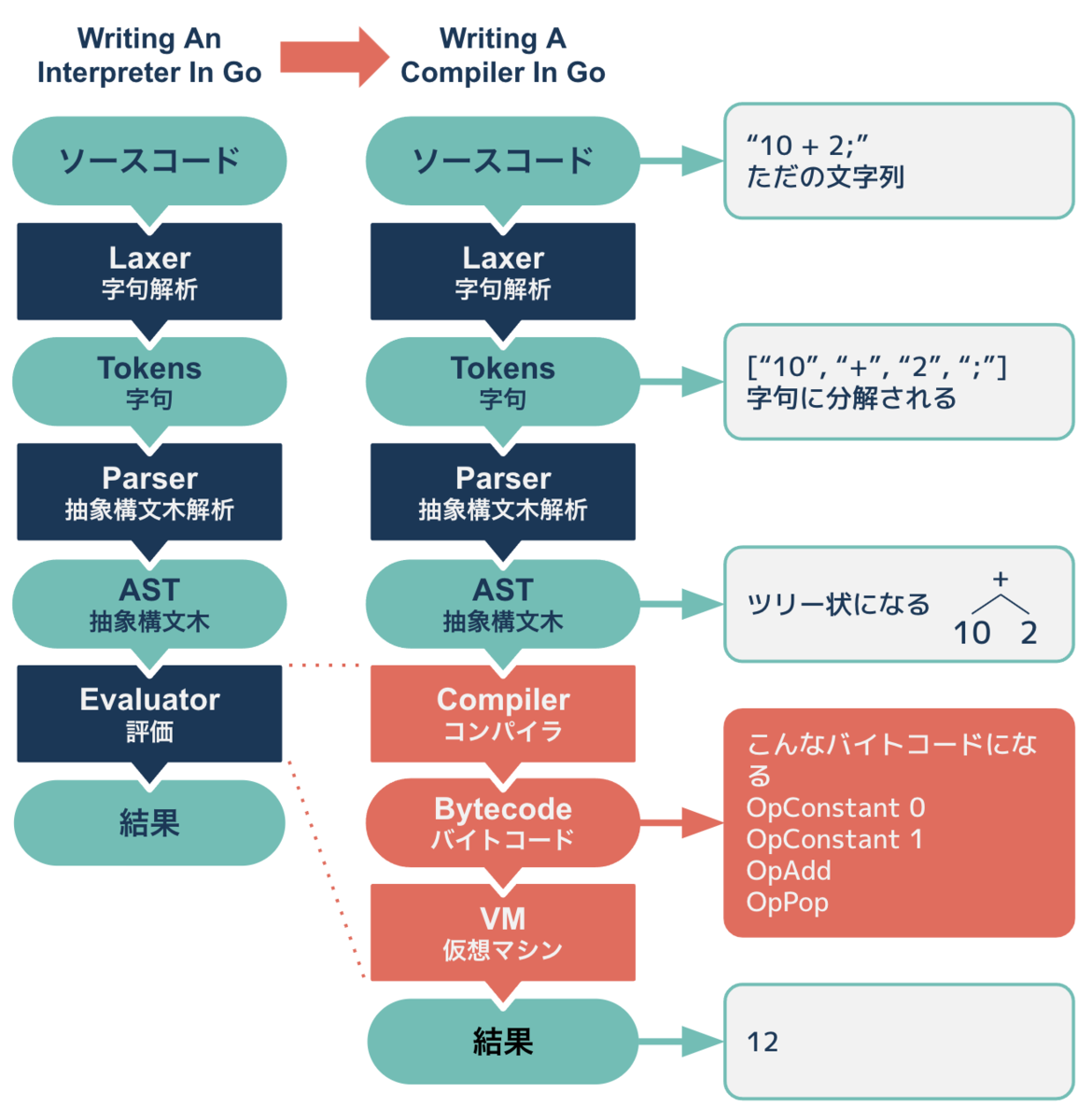
Tree-WalkingインタプリタではASTをたどりながら評価していきましたが、今回この部分を書き換え、コンパイラとVMを追加します。 この変更によりASTから直接評価するのではなく、コンパイラが事前にASTをたどりバイトコード(中間表現)を生成し、そのバイトコードをVMが順に評価することになります。実装方式は変わりますが、得られる結果は書き換える前と同じです。 ※今回実装するVMもインタプリタの実装方式の一種です。JITコンパイラは実装しません。
では、なぜ既に実装ずみのインタプリタをわざわざコンパイラとVMで実装し直すのか、その理由について本書籍では「modular」と「performance」をあげていますが、主な魅力は「performance」と説明しています。仮想マシンを構築することで、より少ない命令で表現できるようになり、結果としてコード密度が高まり、実行速度が向上するということだそうです。 実際書籍の一番最後でフィボナッチ数列のベンチマークを実行し3倍速くなることを確認することになります。
なお、今回オリジナルのMonkey言語をVM方式に書き換えるわけですが、実在する多くのプログラミング言語もライフタイムの中で実行方式をVM方式に書き換えるているらしく、Rubyもその一つとして説明されています。
Rubyがまさにこの例だ。バージョン1.8以下ではtree-walkingインタプリタで、ASTをたどりながら実行する。しかし、バージョン1.9から仮想マシンのアーキテクチャに移行した。
— Go言語で作るインタプリタ - 3章 評価
それでは作成ずみのインタプリタをどのように書き換えるか説明していこうと思いますが、その前にいくつか説明をしておくことがあります。
スタックマシンとバイトコードとデコード
今回実装するVMはスタックマシンです。 スタックは後入れ先出し(Last In First Out)のデータ構造で、これを使って演算します。 例えば1 + 2を実行する場合は ・「1」をスタックにプッシュ ・「2」をスタックにプッシュ ・2つポップして加算したものをプッシュする と順に行うことで、スタックのトップに加算の結果が残り、結果が「3」だということが分かります。

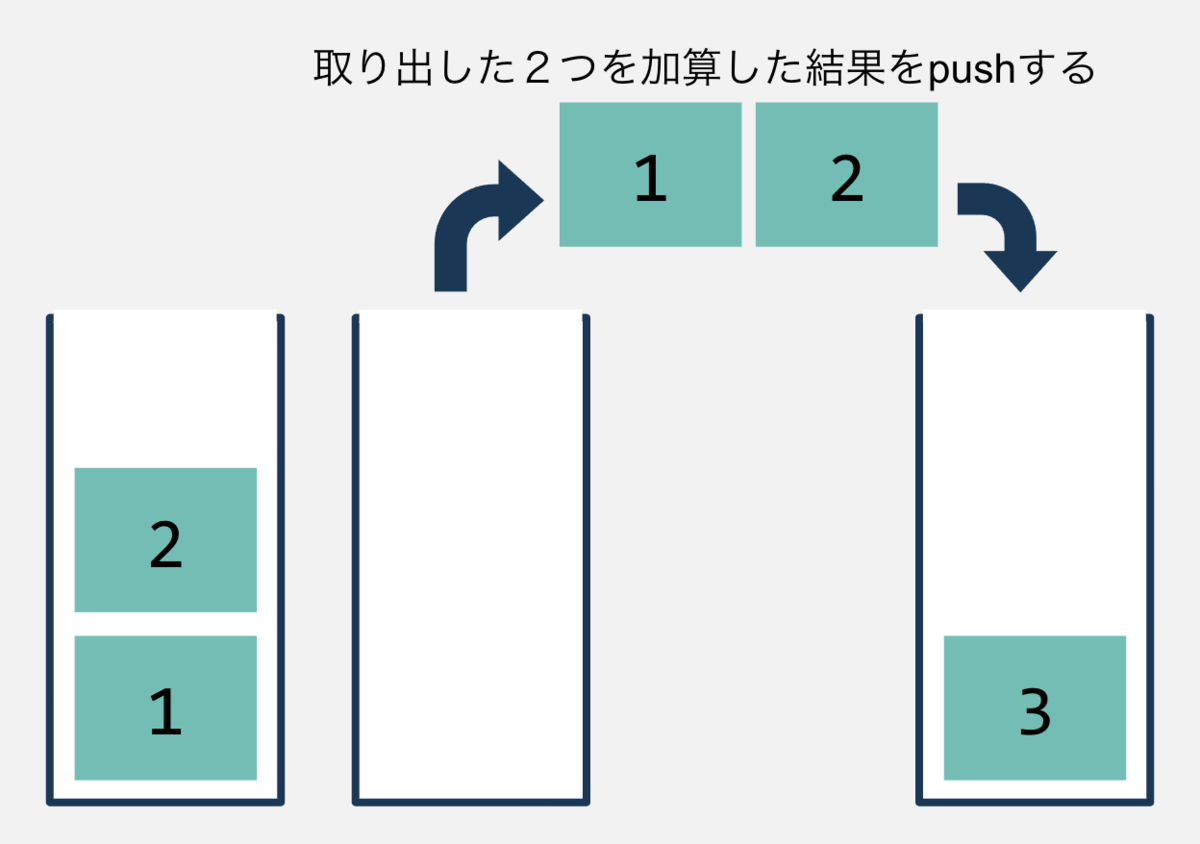
これを実行するバイトコードは以下のように定義されたりします(説明用に単純化した架空のバイトコードで、実際に使われるものではありません)。
PUSH 1 PUSH 2 ADD
しかし実際は上記のようなマルチバイトの文字列ではなく、以下のようなバイナリ表現に変換したバイトコードがVMに渡される事になります。
00000001 00000001 00000001 00000010 00000010
これは下図のような感じでOpecodeとOperandをバイトコードに変換したものです。 ちなみにオペコードの長さが1バイトなのでバイトコードと呼ばれるらしいです。
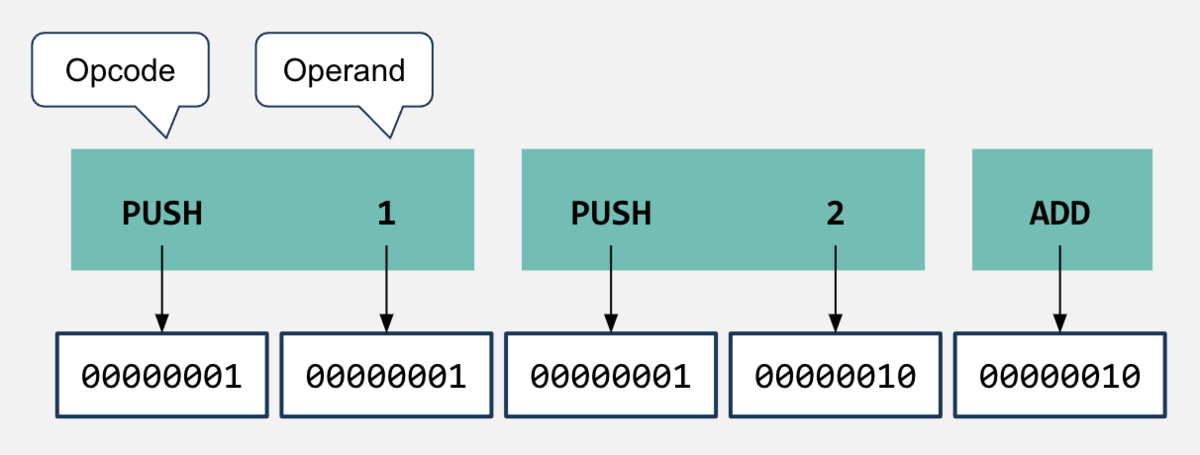
ということで、「00000001 00000001 00000001 00000010 00000010」という謎の数値の羅列がVMに渡されることになりますが、VMはこの数値を受け取ってどのように解釈するのでしょうか。
VMはバイトコードに対して「デコード」「実行」のサイクルをループします。 バイトコードは以下のように評価されます。
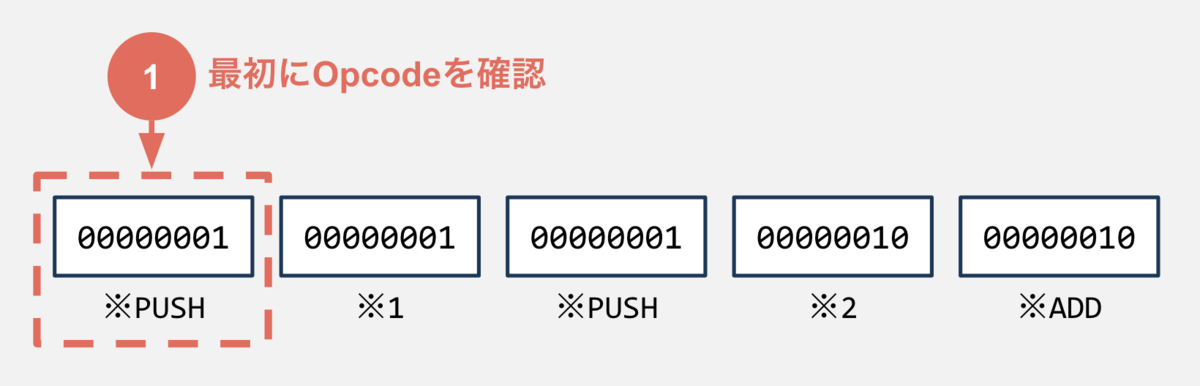
PUSHはOperand(つまり引数)が1つあるので、PUSHの隣のバイトコードも読み取ります。ここまででバイトコードが「PUSH 1」を意味することが分かり、実際にスタックに1をPUSHします。

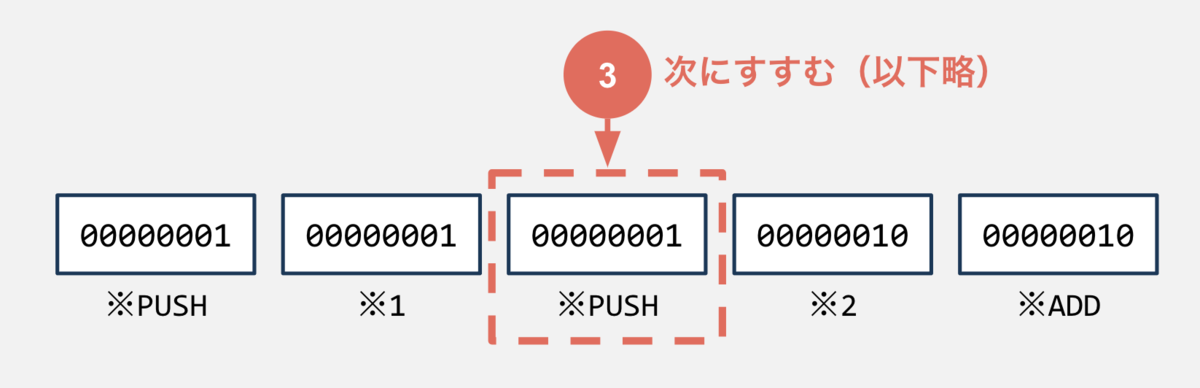
そして、次のOpcodeに処理を進めます。 こんな感じでVMはバイトコードを読み取ることで、次に何をすれば良いかわかるので、それに応じて順次処理を行うことができます。これが大まかな仕組みです。
コンパイラとVM
上記で概念的な説明をしてきましたが、実際に今回作成するコンパイラとVMが何をするか、もう少し具体的に説明します。
定数領域とglobal変数が存在しています。
本書籍で実装するmonkey言語のコンパイラで、
let three = 1 + 2;
をコンパイルすると、定数領域には「1」と「2」が定義された上で、次のようなInstructionが生成されます。
# 定数の0番目をスタックにロードする OpConstant 0 # 定数の1番目をスタックにロードする OpConstant 1 # スタックの上から1番目と2番目を足した結果をスタックに積む OpAdd # グローバル変数に格納する(let文) OpSetGlobal 0 # スタックの一番上をポップする(let文が終わるので) OpPop
VMが実行される前の状態は、下記のようにコンパイラが生成した定数が存在するだけです。
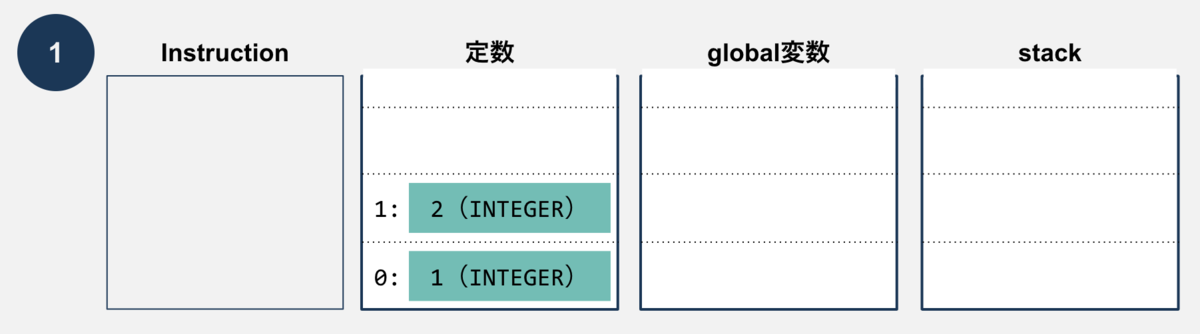
OpConstantが実行されると、オペランド(この例だと0番と1番)で指定された定数をstackにpushします。
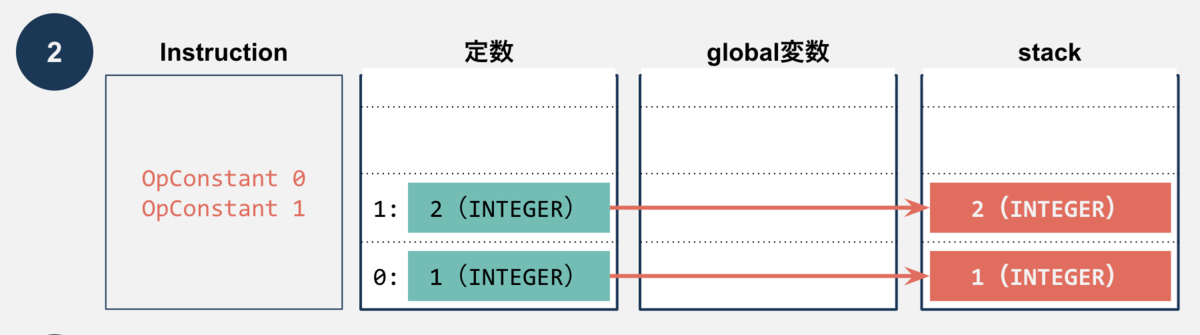
OpAddでstackの上2つをpopして、加算した結果をpushします。
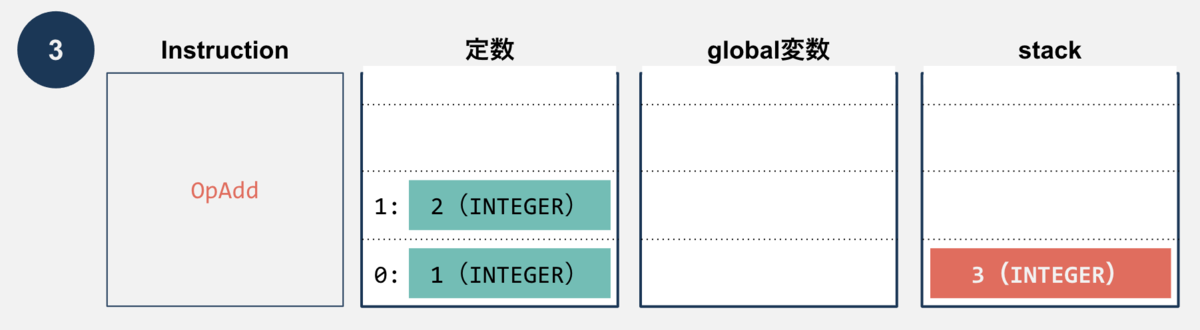
OpSetGlobalでstackのトップをglobal領域にセットします。何番目にセットするかはオペランドで指定されます。

OpPopでstackから1つpopします。

終わりに
条件分岐、関数呼び出し、コールフレームの実装 、クロージャあたりについても書こうと思いましたが、本とソースを読んだ方が速いので、この辺でやめておこうと思います。
非常にシンプルなコンパイラではありますが、私のような凡人プログラマにも実装できました。 興味がある方はぜひ「Writing A Compiler In Go」を読んでみてください。 洋書ですが公式サイトから購入するとHTML版をダウンロードできるので、DeepLのChrome Extensionなどを使えば普通に読めちゃうんじゃないかと思います。
以上です。